Tutorial
Introducing our cutting-edge TextWorker Google Sheet extension that gives you advanced Natural Language and Machine Learning/Artificial Intelligence power inside a standard spreadsheet environment. Tasks such as sifting, labelling, sentiment analysis, press-watching no longer need specialist teams developing custom applications – the people who understand the task can now solve it directly, with the tools already at their fingertips.
With our extension, you’ll be able to analyse and extract insights from your text data with the help of Natural Language Processing (NLP) techniques such as sentiment analysis, entity recognition, and keyword extraction using spreadsheet skills. These features enable you to quickly identify patterns, trends, and insights from your data; you do not need specialist coding skills, and your familiar spreadsheet work is extended without needing the support of specialist data science or AI teams.
Our extension also incorporates Machine Learning and Artificial Intelligence (ML/AI) capabilities, allowing you to train custom models that are tailored to your specific needs. By harnessing the power of ML/AI, you’ll be able to classify text data based on specific criteria, such as topic or sentiment, and quickly sift through large volumes of data to find the information you need.
Entity Extraction
=NLP_ENTITY(target [, outputType [, targetType [, maxReturnValues]]])
- NLP_ENTITY
- Analyse a piece of text to extract persons, organisations, places, or other kinds of entity. Data is returned in one or more columns.
- Syntax
- =NLP_ENTITY(target [, outputType [, targetType [, maxReturnValues]]])
- Target is the text to be analysed, which can be in a single cell or in a range of contiguous cells.
- OutputType optionally specifies the kind of data to be output. Default is blank to report the entity’s name, type and a link to a dbpedia.org article about the entity, if one is found. Other permitted values are 0 for label only i.e. the entity’s name, 1 for a link (URL) only and 2 for the entity type only.
- TargetType optionally filters the query. Default is blank for all types the model can identify. Values can be entered as free text, for example, “Person”, “Location”, or “Organisation”. You can filter on more than one type by entering types separated by commas: “Location, Person”.
- The filtering by targetType works best with the following standard categories: Person, PersonType, Location, Organization, Event, Product, Skill, Address, PhoneNumber, Email, URL, IP, DateTime, Quantity.
- It is, however, possible to filter by other targetTypes, for example, “Animal” or “Book”. You will probably get useful results, but they may be inconsistent.
- Optionally set maxReturnValues to limit the number of results returned. This can be useful if you have a long input text. Default is unlimited. If this value is set, the function will return up to this number of entities for each identified entity type. To show a limited number of entities of a particular type, combine maxReturnValues and targetType.
- If NLP_ENTITY can find no matching entities for the parameters you have set, it will return the value “No Entities Found”.
- Usage
- =NLP_ENTITY(A1:A3) extracts the name, type and a dbpedia.org link, of all entities found in the text in A1 to A3 and returns the list in columns as in the example:

Summarization
NLP_SUMMARIZE
Summarise and compress a block of text.
Syntax
=NLP_SUMMARIZE(input, compressionFactor)
Input is the text to summarise and can be either a text input or a reference to either a cell or range.
CompressionFactor is the amount, expressed as a decimal, to which the function should attempt to reduce the text. Thus 0.75 requests an output that is 75% of the length of (i.e. 25% shorter than) the input text. As summarisation requires meaning to be preserved, consider CompressionFactor to be a guide rather than a rigid target.
Note: since the function explicitly summarises text, compressionFactor values greater than 1 are disregarded. Using a compressionFactor value near 1 is likely to yield poor results, as the function attempts to deliver a genuine summary that reflects the meaning of the input text.
Usage
=NLP_SUMMARIZE(“some long text here”, 0.6) returns a summary of the input text, compressed to 60% of its original length.
=NLP_SUMMARIZE(B6:B8, AVERAGE(C1,D1)) returns a summary of the text in cells B6 to B8, compressed to the average of the values in C1 and D1.
NLP_RELEVANCE
Score text against a list of classifications that you provide. The scores are an estimate of the relevance of the text to the classifications and are numbers between 0 and 1, with 1 being ‘most relevant’. The results are returned in a row or in a column, depending on the layout of the classification list.
Syntax
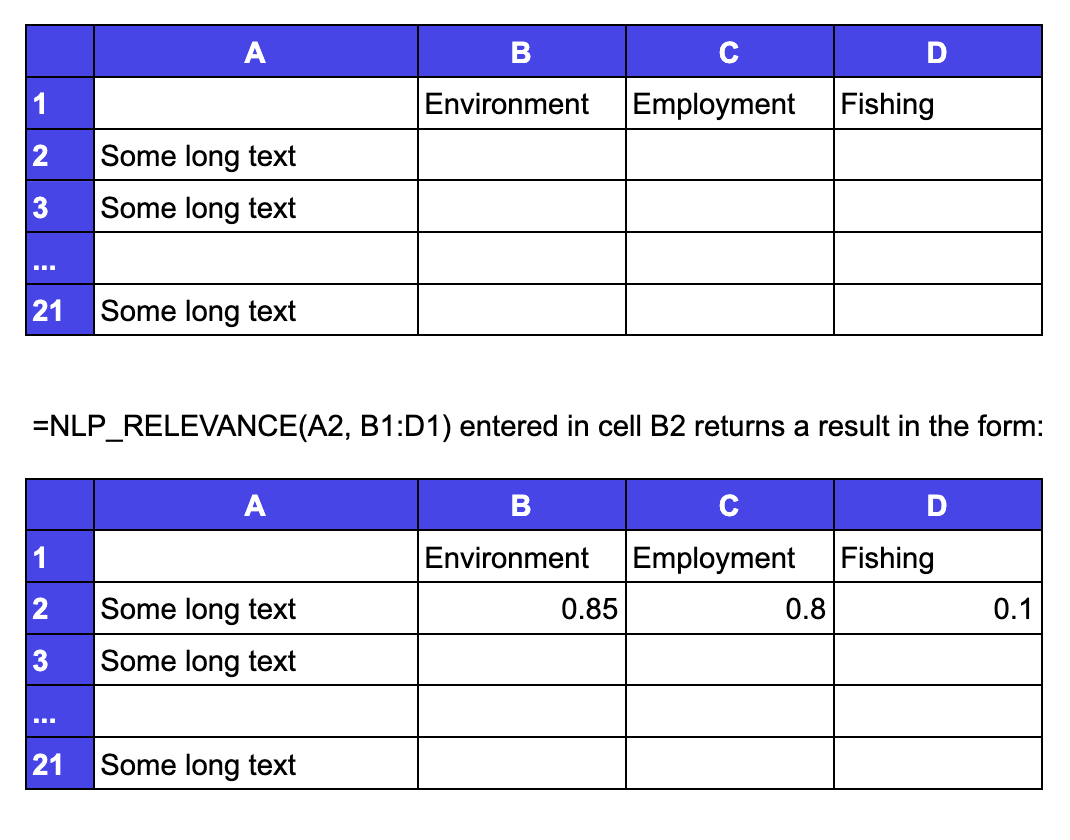
=NLP_RELEVANCE(target , classificationList)
Target is the text to be analysed, which can be in a single cell or in a range of contiguous cells.
ClassificationList is a range containing the classifications against which Target is to be analysed. The list must be provided and must be either a single row with multiple columns or a single column with multiple rows. Each cell in ClassificationList will be understood to be a single classification or topic to consider.
Usage
Suppose you want to analyse 20 separate bits of text in cells A2 to A21 and obtain relevance scores against the classifications Environment, Employment, Fishing. These values are in cells B1 to D1.
NLP_FINDTOPICS
List the prevalent topics found in a block of text. This can quickly analyse texts for further action, or create a list against which to analyse other texts, for example with NLP_RELEVANCE.
Syntax
=NLP_FINDTOPICS(target, maxTopics [, lookup])
Target is the text to be analysed and can be either directly input or a cell or range reference.
MaxTopics is the number of topics you want listed and can be a number or a cell reference.
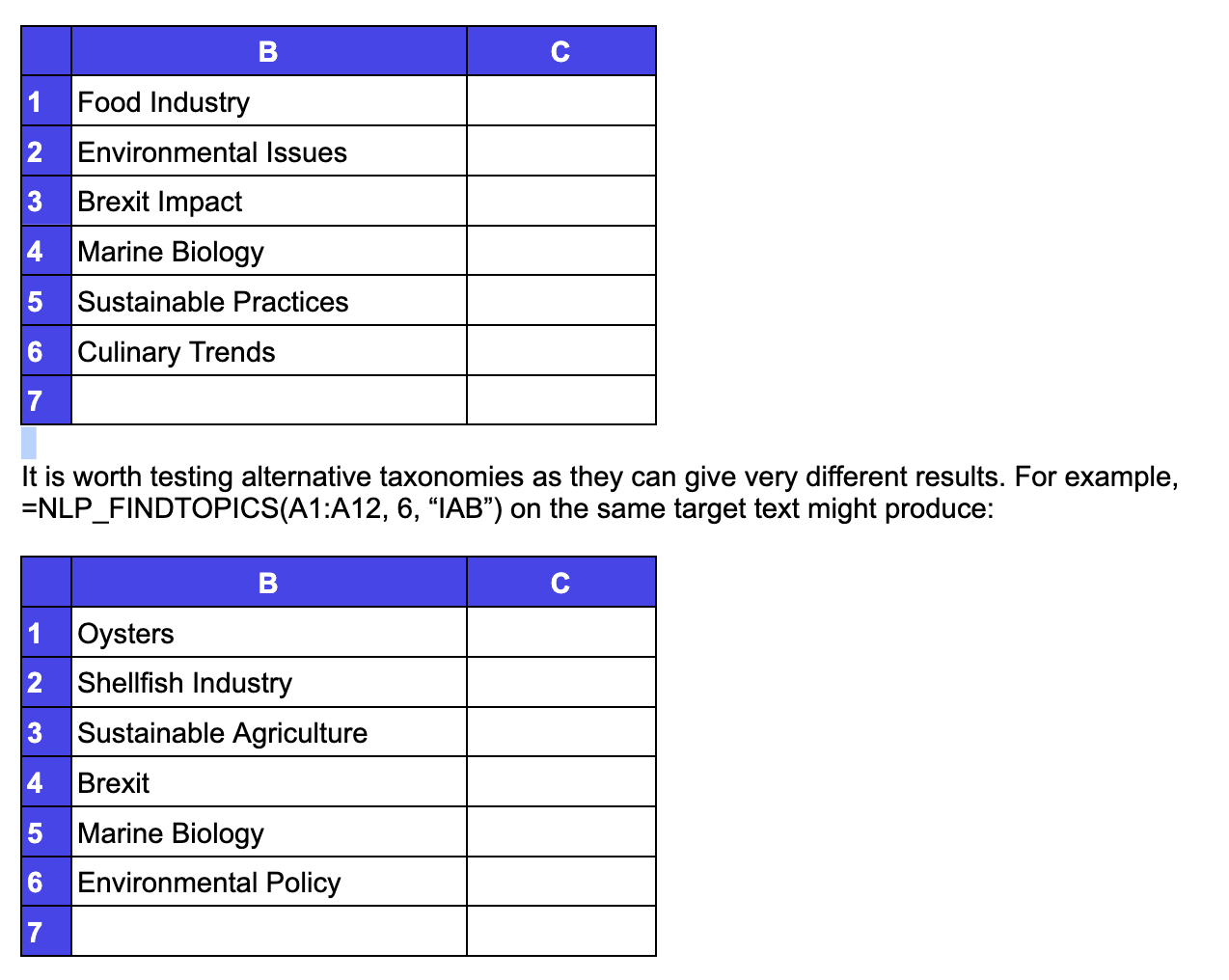
Lookup is the taxonomy from which to establish the list of topics. The default is to leave Lookup blank, in which case the function asks the AI model to use its own best estimates. The other option currently available directly is “IAB”, which will use the taxonomy of the International Advertising Board. You can enter arbitrary text here to specify a different taxonomy. If you do so, the LLM will make its best guess to interpret what you want. You will likely have to experiment until you get the most useful results.
Usage
=NLP_FINDTOPICS(A1:A12, 6) will list the top 6 topics found in the text contained in cells A1 to A12 and return data in the form:
PROMPT
NLP_PROMPT
Submit a freeform request optionally based on a block of input text. This is equivalent to asking a question of an AI model directly, but returning the reply in your spreadsheet.
Syntax
=NLP_PROMPT(prompt [, reference [, systemMessage]])
Prompt is the command you send to the NLP engine and can be either a text input or a reference to a cell or range.
Reference is optionally the text against which you wish the command to run and is typically a reference to a cell or range. It can be a text input. If Reference is not provided, Prompt should be a free-standing question.
systemMessage is an optional message to the model that directs the system to a particular mode or approach.
Usage
=NLP_PROMPT(A1, B1:B12) where A1 contains “Please list the key topics as bullet points and single sentences” and B1:B12 contains the text you want analysed.
=NLP_PROMPT(A1,,C1) where A1 contains “Summarise the principal suppliers in the UK of consumer broadband services” and C1 contains “You are a marketing research assistant who diligently works to answer questions truthfully and accurately”.
=NLP_PROMPT(A1) where A1 contains “Give me 5 suggestions for books to read about existentialism”.